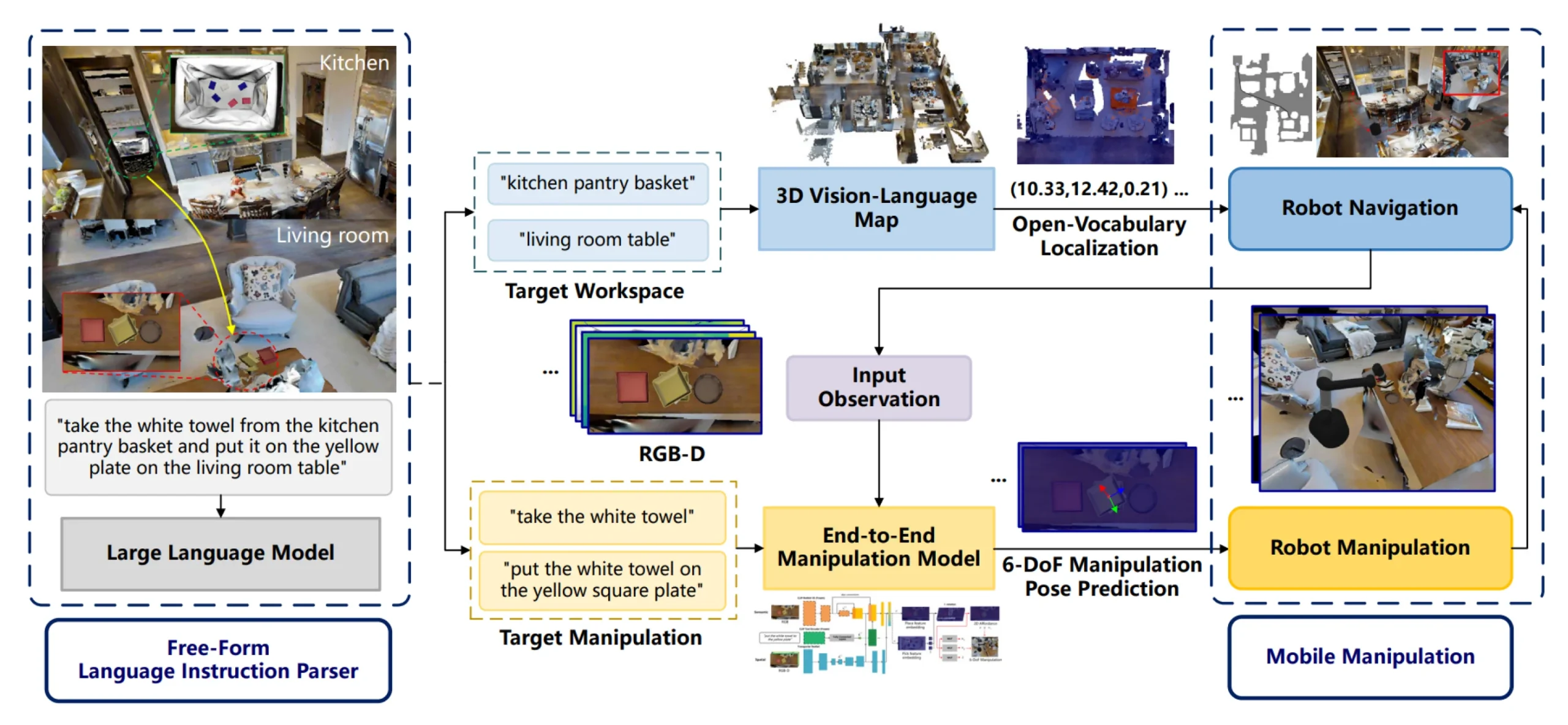
我们项目的核心在于具身智能(Embodied Intelligence)的整合,使机器人能够在真实的家庭环境中感知、推理并采取行动。与仅专注于静态任务的传统 AI 系统不同,具身智能需要与物理环境进行动态交互。通过利用 视觉-语言-动作 (Vision-Language-Action, VLA) 框架,我们致力于大幅提升机器人在室内场景中执行复杂操作任务的能力。
我们的数据采集管线从真实家庭环境中捕获连续的视频和图像序列,记录机器人在其中的导航与物体操作过程。我们的目标是建立丰富的、具备上下文感知能力的大模型,使机器人即使在不断变化的环境中也能高效完成任务。
同时,我们通过采集器上的传感器与 深度相机 (RGBD cameras) 收集机器人的操作数据,精准捕捉机器人与物体的交互细节。收集的数据维度包括视觉流、末端执行器动力学 (End-effector dynamics) 以及动作序列——涵盖了抓取、移动和放置等精细化操作。

模型训练阶段,我们将这些视觉与动作数据与自然语言指令进行了深度结合。通过集成预训练的 大型语言模型 (LLMs) 和 视觉-语言模型 (VLMs),我们的机器人能够精准理解人类下达的开放式指令,并将其转化为可执行的物理动作任务。
我们的端到端(End-to-end)训练管线专为处理和融合多模态数据而设计,使机器人不仅能在陌生的环境中导航,还能执行高精度的操作任务。这种 零样本泛化 (Zero-shot generalization) 能力,确保了系统能够在各种未见过的长尾环境中依然稳健运行。
由我们生成的具身智能数据集已完成闭环的可用性验证。图为使用我们数据训练的演示机械臂,它能够自动感知并分类地面杂物,将其精准收纳至指定位置。


专为具身智能打造的高精数据集。依托规模化的真实物理世界采集阵列,我们致力于解决长尾场景缺失难题,为您提供高质量、多模态的训练数据,加速机器人的端到端落地。
涵盖全球范围内多样化的真实家庭场景,以及高度非结构化的复杂物理环境。
每日持续更新,确保针对新兴场景与长尾边缘案例 (Edge-case) 需求的极速响应。
内置丰富的任务标签,支持抓取、叠放、避障等多种具身智能模型训练的核心操作任务。
严格执行个人隐私保护机制,支持对人脸、车牌及敏感证件信息的自动化脱敏与模糊处理。